Active learning framework leveraging transcriptomics identifies modulators of disease phenotypes | Science
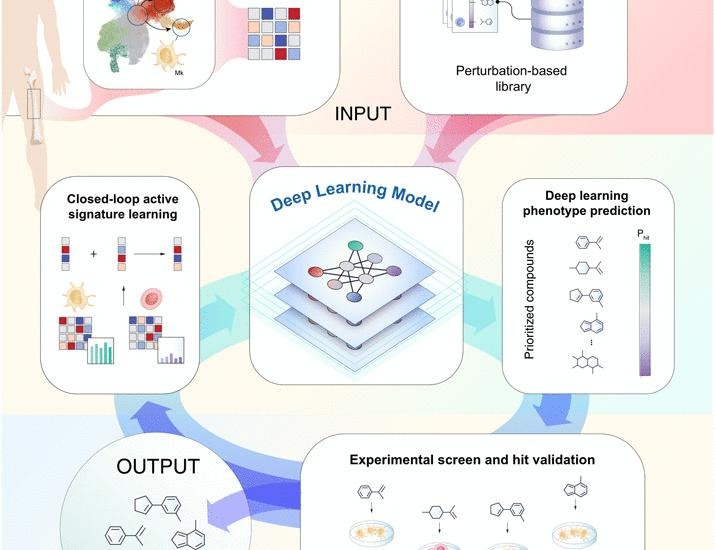
Phenotypic drug screening, a crucial process in drug discovery, faces significant challenges due to the immense diversity of potential chemical compounds and the complexities involved in scaling experimental workflows. Traditionally, this method involves observing the effects of various compounds on biological systems without prior knowledge of specific targets, making it a powerful approach for discovering new therapeutics. However, the sheer volume of chemical space—estimated to contain billions of potential compounds—poses a daunting task for researchers. The need for efficient and effective screening methods has led to the integration of computational techniques designed to prioritize compounds based on their predicted efficacy and safety profiles.
Recent advancements in computational methods have shown promise in addressing these challenges, enabling researchers to narrow down the vast chemical landscape to a more manageable set of candidates. For instance, machine learning algorithms can analyze existing biological data and chemical properties to predict how new compounds might interact with biological targets. These predictive models not only enhance the speed of the screening process but also improve the likelihood of identifying viable drug candidates. However, these computational approaches are not without their limitations; they often rely on high-quality datasets and can struggle with the inherent complexity of biological systems, which may lead to inaccurate predictions if the models are not properly validated.
To maximize the efficacy of phenotypic drug screening, a hybrid approach that combines computational predictions with experimental validation is increasingly being advocated. This approach allows researchers to leverage the strengths of both methods, using computational tools to prioritize compounds while still conducting rigorous laboratory tests to confirm their biological activity. By integrating computational and experimental workflows, scientists can more efficiently navigate the complexities of drug discovery, ultimately accelerating the development of new treatments for a range of diseases. As the field continues to evolve, the collaboration between computational and experimental researchers will be key in overcoming the hurdles posed by the vastness of chemical space and the intricacies of biological interactions.
Phenotypic drug screening remains constrained by the vastness of chemical space and the technical challenges of scaling experimental workflows. To overcome these barriers, computational methods have been developed to prioritize compounds, but they rely …


